
...making Linux just a little more fun!
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to bytes@linuxgazette.net. Deividson can also be reached via twitter.
 Russia's Prime Minister Signs Order to Move to Open Source
Russia's Prime Minister Signs Order to Move to Open SourceAs reported in Glyn Moody's Open blog, Prime Minister Vladimir Putin has ordered Russian government agencies to switch to open source software by 2015. The transition is due to begin during the second quarter of 2011. The Russian government also plans to build a unified national repository for open source software.
According to Moody, previous attempts to move parts of the Russian government to open source software had experienced a lukewarm reception due to a lack of political support. However, he writes, "if Putin says: 'make it so,' I suspect that a lot of people will jump pretty fast to make sure that it *is* so. [...] once that happens, other plans to roll out free software might well suddenly look rather more attractive."
The order mandates a broad set of related changes in education at all levels, including professional training for federal and civilian employees. It also covers a number of specific directives for the ministries of health, science, and communications, and specifies the implementation of "open source operating systems, hardware drivers, and programs for servers and desktop use."
The Business Software Alliance, a trade group representing large U.S. software vendors, estimates that 67 percent of software used in Russia in 2009 was pirated.
[ Given that the net effect of "pirated" software is,
and has always been, a positive benefit to the members of the Alliance - no
actual cost for the software distribution, and a large pool of IT people
trained in the use of their platforms and products - it's interesting to
speculate on the eventual result of these changes with regard to those
members. It seems that trading on that particular "pity bait" is coming to
an abrupt end...
-- Ben Okopnik ]
Linux Foundation's Annual 'Who Writes Linux' Study ReleasedThe Linux Foundation has published its annual report on Linux kernel development, detailing who does the work, who sponsors it and how fast the Linux kernel is growing.
As Amanda McPherson states in her blog, this paper documents how hard at work the Linux community has been. There have been 1.5 million lines of code added to the kernel since the 2009 update. Since the last paper, additions and changes translate to an amazing 9,058 lines added, 4,495 lines removed, and 1,978 lines changed every day, weekends and holidays included.
A significant change this year was the increasing contributions by companies and developers working in the mobile and embedded computing space. For more information on the study, see the blog entry here: http://www.linuxfoundation.org/news-media/blogs/browse/2010/12/our-annual-kernel-development-report-new-and-old-faces.
Novell Agrees to be Acquired by Attachmate CorporationIn November, Novell entered into a definitive merger agreement under which Attachmate Corporation would acquire Novell for $6.10 per share in cash, which was valued at approximately $2.2 billion. Attachmate Corporation is owned by an investment group led by Francisco Partners, Golden Gate Capital and Thoma Bravo. Novell also entered into a definitive agreement for the concurrent sale of certain intellectual property assets to CPTN Holdings LLC, a consortium of technology companies organized by Microsoft Corporation, for $450 million in cash. That sale of IP assets has raised some concerns in the Open Source community.
Attachmate Corporation plans to operate Novell as two business units: Novell and SUSE; and will join them with its other holdings, Attachmate and NetIQ.
The $6.10 per share consideration represents a premium of 28% to Novell's closing share price on March 2, 2010, and a 9% premium to Novell's closing stock price on November 19, 2010. Since the merger was announced, 2 shareholder suits have been filed questioning the deal.
"After a thorough review of a broad range of alternatives to enhance stockholder value, our Board of Directors concluded that the best available alternative was the combination of a merger with Attachmate Corporation and a sale of certain intellectual property assets to the consortium," said Ron Hovsepian, president and CEO of Novell. "We are pleased that these transactions appropriately recognize the value of Novell's relationships, technology and solutions, while providing our stockholders with an attractive cash premium for their investment."
There was some concern in the blogosphere that this patent portfolio might strengthen Microsoft's hand with regard to Linux. However, many are expected to reflect on Novell's Office and collaboration products.
Groklaw's November post Novell Sells Some IP to a MS-Organized Consortium asks "...so what goes to Microsoft's consortium? No doubt we'll find out in time. It is being reported that what it will get is 882 patents. Blech. How many does Novell own? Is that all of them? If so, will we get to watch Son of SCO, but with patents this time? But keep in mind that the WordPerfect litigation could be in this picture, and I wonder if this could be a kind of deal to tactfully settle it out, with Microsoft paying to end it this way?"
Groklaw also notes that prior contracts and promises made by Novell will probably remain in force: "As for the question of what happens to prior promises Novell made, if they are contractual, you go by the contract. In a stock for stock merger, I'm told by a lawyer, all obligations remain in force. In an asset sale, the two negotiate who gets what. But if the buyer *takes over* a contract, then they have to honor all of the terms of the contract, such as a patent license or cross license."
Attachmate Corporation's acquisition of Novell is subject to customary closing conditions and is expected to close in the first quarter of 2011.
Red Releases RHEL 6 In mid-November, Red Hat Enterprise Linux 6 was delivered with over three years' worth of customer-focused product innovation for advancing data-center efficiency.
In a blog post, Tim Burke, Vice President, Linux Development at Red Hat stated:
"In my development team we feel a tremendous sense of pride in that we have the privilege of being at a confluence point of technology innovation and customer need fulfillment. This gives us a full life-cycle of gratification in that we get to build it, test it, harden it and learn from this where the next iteration of technology advancement may flow. Red Hat is well positioned to provide the 10-year support life-cycle for Red Hat Enterprise Linux 6 - nobody can support something better than the team that leads the technology building and integration. From our perspective, there's no greater praise than to see the releases harnessed by customers - that's a win-win situation."
Some notable enhancements among the literally several thousand comprising Red Hat Enterprise Linux 6:
- up to 2X improvement in network rates; - 2X to 5X improvement in multi-user file-system workloads; - Virtualization I/O enhancements allowing increased consolidation (more guests per host) while at the same time reducing I/O overhead significantly in comparison to bare metal.
- Control groups - enables the system administrator to control resource consumption - for network & disk I/O, memory consumption and CPU utilization.
- Svirt - refers to SELinux-based security enhancements for virtualization - enabling policy to constrain each virtualized guest's ability to access resources like files, network ports and applications. This forms a two-layer check and balance system whereby in a multi-tenancy environment if one guest were able to exploit a vulnerability in the virtualization layer, the enhanced policy is designed to block that guest from accessing resources of other virtualized guests or the host platform.
- More Efficient IT - from a power consumption perspective, the most efficient CPU is the one that is powered off - especially important for large systems - ie: 64 CPUs. Red Hat Enterprise Linux 6 combines a new system scheduler with more intimate knowledge of the low-level hardware topology to yield a 25 percent reduction in power consumption versus Red Hat Enterprise Linux 5 for a lightly loaded system - by intelligently placing underutilized CPUs (and other peripherals) into low power states.
- Enhanced resilience and isolation of hardware failures with fine-grained error reporting to mark faulty memory pages as unusable, plus hardware based memory mirroring and failing peripheral isolation. Integration of hardware-based data check-summing at the storage level for improved end-to-end data integrity.
- A new automated bug reporting utility that captures the state of applications and system service crashes and can aggregate this information either centrally on premise or to automatically log incidents with Red Hat support.
The KVM-based virtualization scalability benefits from work with component providers and several peripheral vendors to optimize hardware I/O accelerators. The Red Hat Enterprise Linux 6 kernel is based on the upstream 2.6.32 kernel (of which Red Hat is independently recognized as the leading contributor).
A Red Hat Enterprise Linux 6 example of openness is libvirt - a Red Hat initiative delivering a high-level management interface to virtualization. This abstraction layer is designed to insulate customers from system specific quirks in configuration and management. Providing choice at the hardware level, Deltacloud provides an abstraction layer aimed at insulating customers from lock-in at the cloud provider layer. Red Hat Enterprise Linux 6 contains what will be a growing foundation of Deltacloud platform enablers.
FreeBSD 8.2-BETA1, 7.4-BETA1 Development ReleasesNow available: first beta releases of FreeBSD 8.2 and 7.4, new upcoming versions in the the production (version 8) and the legacy production (version 7) series. The first of the test builds for the 8.2/7.4 release cycle is available for amd64, i386, ia64, pc98, and sparc64 architectures. Files suitable for creating installation media or doing FTP-based installs through the network should be on most of the FreeBSD mirror sites. The ISO images for this build do not include any packages other than the docs. For amd64 and i386, 'memstick' images can be copied to a USB 'memory stick' and used for installs on machines that support booting from that type of media.
The freebsd-update(8) utility supports binary upgrades of i386 and amd64 systems running earlier FreeBSD releases. Systems running 8.0-RELEASE or 8.1-RELEASE can upgrade simply by running
# freebsd-update upgrade -r 8.2-BETA1
Users of earlier FreeBSD releases (FreeBSD 7.x) can also use freebsd-update to upgrade to FreeBSD 8.2-BETA1, but will be prompted to rebuild all third-party applications (e.g., anything installed from the ports tree) after the second invocation of "freebsd-update install", in order to handle differences in the system libraries between FreeBSD 7.x and FreeBSD 8.x. Substitute "7.4-BETA1" for "8.2-BETA1" in the above instructions if you are targeting 7.4-BETA1 instead.
MySQL 5.5 Features New Performance and Scalability EnhancementsShowing its commitment to MySQL users, Oracle announced in December the general availability of MySQL 5.5, which delivers significant enhancements in performance and the scalability of web applications across multiple operating environments, including Linux, Solaris, Windows, and Mac OS X.
The MySQL 5.5 Community Edition, which is licensed under the GNU General Public License (GPL), and is available for free download, includes InnoDB as the default storage engine. This release benefited from substantial user community participation and feedback on the MySQL 5.5 Release Candidate, helping to provide a more broadly tested product.
With MySQL 5.5, users benefit from:
- Improved performance and scalability: Both the MySQL Database and
InnoDB storage engine provide optimum performance and scalability on
the latest multi-CPU and multi-core hardware and operating systems. In
addition, with release 5.5, InnoDB is now the default storage engine
for the MySQL Database, delivering ACID transactions, referential
integrity and crash recovery.
- Higher availability: New semi-synchronous replication and
Replication Heart Beat improve fail-over speed and reliability.
- Improved usability: Improved index and table partitioning,
SIGNAL/RESIGNAL support and enhanced diagnostics, including a new
PERFORMANCE_SCHEMA, improve the manageability of MySQL 5.5.
In recent benchmarks, the MySQL 5.5 release candidate delivered
significant performance improvements compared to MySQL 5.1,
including:
- On Windows: Up to 1,500 percent performance gains for Read/Write
operations and up to 500 percent gain for Read Only.
- On Linux: Up to 360 percent performance gain in Read/Write
operations and up to 200 percent improvement in Read Only.
For more details, replay the MySQL Technology Update web-cast from Dec. 15th: http://bit.ly/eS99uo.
SPARC M-Series Servers with New CPU for Mission-Critical ComputingContinuing a 20-year partnership in mission-critical computing, Oracle and Fujitsu announced in December the enhanced SPARC Enterprise M-Series server product line with a new processor SPARC64 VII+. Oracle and Fujitsu also unveiled the unified enclosure design of the Oracle and Fujitsu SPARC Enterprise M-series servers which are jointly designed and manufactured by Oracle and Fujitsu.
The new SPARC64 VII+ processor provides faster memory access and
increased compute power, including:
- Increased clock speed of up to 3.0 GHz and double the size of the
L2 cache up to 12MB, delivering up to 20 percent more performance.
- SPARC hardware and Oracle Solaris jointly engineered for maximum
performance.
The SPARC Enterprise M-series servers with Oracle Solaris provide
mission-critical reliability, availability and serviceability (RAS)
for applications that need to be "always on" including:
- Predictive self-healing, component redundancy and hot-swap, memory
mirroring and fault containment with Dynamic Domains and Solaris
Containers.
- Extensive combined hardware, operating system and application
testing to improve reliability and performance of the servers.
The recently announced Oracle Enterprise Manager 11g OpsCenter has new
SPARC Enterprise M-series-specific management capabilities, including:
- Simplified management for the entire integrated hardware and
software stack.
- The ability to create, manage, provision and configure Dynamic
Domains and Solaris Containers, making the SPARC Enterprise M-Series
servers a better consolidation platform.
The SPARC Enterprise M-Series servers are Oracle and Fujitsu's comprehensive line of SPARC Solaris servers, ranging from the single-socket M3000 to the 64-socket M9000. This announcement completes a full refresh of Oracle and Fujitsu's entire line of SPARC servers.
Google releases Chrome OS and netbook for XmasIn early December, with the announcement of a Chrome 8 browser update and its Chrome-OS beta, Google also opened a pilot program for diverse users. Unlike the social engineering emails of the 1990s that falsely lured responders with offers of a Microsoft laptop, there really is a Google netbook and many folks got one before the Xmas holiday.
The browser update includes 800 bug fixes, better HTML 5 support, a built-in PDF reader, and integration of graphics acceleration. At its press event at a San Francisco art gallery, engineers displayed a 3D aquarium app that could be scaled up to thousands of fish with correct perspective. The message was that the Chrome browser offers significantly improved performance. In a demo, engineers loaded all 1990 pages of the recent health care law in seconds and smoothly scrolled through it. Google also said that the new Chrome 8 browser would be released for all major platforms, including Linux and Mac.
The star of the event was the much anticipated beta of the Chrome OS. This is actually a very stripped down version of Debian Linux supporting only the web browsing app. It ties into security hardware, like TPMs [trusted programming modules], and is designed to boot in seconds. What wasn't expected was the CR-48 beta test platform and the fact that these netbooks were shipping immediately. Even more unexpected was the fact that the public was invited to participate in the beta by receiving a free CR-48 after applying on-line.
Google is looking for diverse and even unusual web browsing activity to collect info on how the Chrome OS handles all web browsing requirements. There may be a preference for users of on-line applications and SaaS. You can apply for the Pilot program here: http://google.com/chromenotebook.
According to press reports, Google has 60,000 CR-48s on order from Taiwanese manufacturer Inventec and that about 15,000-20,000 had arrived by the announcement date. Some of these were immediately made available to trade press and technical publications, as well as Google staff.
The CR-48 is a cool black Linux netbook with running a tightly coupled version of the Chrome Browser. Its a web machine, designed as a web top without the option of a desktop - unless you put it in the secret developer mode where the underlying Linux OS is available for testing or hacking. It is designed to live in the Cloud, storing only some user info and preferences locally.
Google has called it a laptop, mostly due to its 12 inch display and full size key pad. But it weighs in at just under 4 pounds with 2 GB of RAM and an N455 Atom processor. Many newer netbooks already use the dual core 500 series of Atom CPUs, but the real performance hit is in the slow links to the graphics sub-system. AMD has recently released a dual-core Atom-class processor with an integrated graphics core and such a chip should greatly outperform the current Atom family in the rendering and multi-media area. (see the Product section below).
The low power Atom CPU and Mac-like Lithium polymer battery yield a claimed 8 hours of use and 8 days of standby. (Our experience at LG with a test machine was more like 6 hours plus and about 6 days of standby, but the battery may have been short of a full charge.) The CR-48 looks like an older 13 inch MacBook and is frequently mistaken for one.
The Google netbook supports WiFi, Bluetooth, and a 3G cellular adapter with 100 MB/month Verizon service for free as a standby when WiFi is not available. Larger data plans are available from Verizon starting at $10 per month.
These specifications should be expected when Chrome OS powered devices from Acer and Samsung start making their debut some time next year. It is also very likely that we will begin to see demo's of such devices during CES in January.
Some press reports note the over-sized touchpad is over-sensitive and the Adobe Flash plug-in for Linux has had awful performance, but both Adobe and Google engineers are working on it.
To see what's inside the CR-48, go here: http://chromeossite.com/2010/12/11/google-cr-48-notebook-dissected-pictures/.
There is also an open source project and community around the code base, http://chromiumOS.org.
From the FAQ page: "Chromium OS is the open source project, used primarily by developers, with code that is available for anyone to checkout, modify and build their own version with. Meanwhile, Google Chrome OS is the Google product that OEMs will ship on Netbooks this year."
For more info, see: http://www.chromium.org/chromium-os/chromium-os-faq.
Here is an initial list of netbooks that were tested with the open source Chromium OS: http://www.chromium.org/chromium-os/getting-dev-hardware/dev-hardware-list.
AMD Gears up for its Fusion Family of APUsIn December, AMD announced a new lineup of motherboard products for AMD's 2011 low-power mobile platform (code-named "Brazos") and the AMD Embedded G-Series platform for embedded systems (code-named "eBrazos"), both based on the first AMD Fusion Accelerated Processing Units (APUs). The 2011 low-power mobile platforms feature the new 18-watt AMD E-Series APU (code-named "Zacate") or the 9-watt AMD C-Series APU (code-named "Ontario").
"AMD is ushering in a new era of personal computing, and our industry partners are ready to take advantage of the first ever AMD Fusion APU," said Chris Cloran, Corp. VP and GM, Computing Solutions Group, Client Division, AMD. "By combining the processing of the CPU with the GPU on a single energy efficient chip, we believe their customers can take advantage of better price/performance, superior 1080p HD playback and small form factors for innovative designs."
During Intel's Developer Forum, AMD held preview sessions showing low-power Zacate netbook chips matching or besting a 35-watt commercial laptop running an Intel Core I-5 CPU and standard Intel GPU. In a recent Taiwan computer fair, MSI showed off an 11.6 inch netbook that will shown at CES that is based on the Zacated APU with 4 GBs of RAM.
Numerous motherboard designs based on the AMD E-Series APU are planned for retail channels and system builders from leading original design manufacturers (ODMs), including ASUS, GIGABYTE, MSI and SAPPHIRE. Additional motherboard designs based on the AMD Embedded G- Series platform for embedded systems are scheduled for Q1 2011 availability to enable the next generation of embedded computing devices from digital signage and medical imaging to casino gaming machines and point-of-sale kiosks.
"With the new AMD E-Series APU, we can provide our customers the cost-effective solutions they're looking for to build PCs with unrivalled image quality," said Joe Hsieh, Vice President of ASUS. "Our AMD E-Series APU-based motherboards redefine the low-power, small PC experience to go beyond basic Internet browsing for today's digital lifestyle."
| Share |

|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

By Silas Brown
The Mutt email client is very useful, especially for dealing with large volumes of mail, but it might need careful configuration. This article explains a few points about configuring Mutt.
The first problem I'd like to address is the Mutt+Exim BCC privacy leak. By default, mutt relies on the MTA (mail transfer agent) to remove the BCC (blind carbon copy) headers from messages. Some MTAs such as Exim will not do this by default, or at least not the way Mutt calls them. Therefore, it is possible that your BCC headers will be visible to all parties. In some circumstances this could be a major privacy leak. Moreover, your Mutt might be configured to hide BCC headers on incoming mail, so if you think you're safe because you sent yourself a test message and didn't see its BCC header, think again! Check the full headers for BCC lines. Your correspondents on Yahoo and GMail et al will see them if they're there.
I know a university that actually removed Mutt from its Linux systems due to the potential seriousness of this problem, but there are several possible workarounds:
This is what most .muttrc writers seem to do and it's the easiest. Set write_bcc=no in your .muttrc and BCC headers will never be written to messages at all (but the blind carbon copies can still be sent).
The documentation for mutt's write_bcc option (which defaults to YES) is slightly confusing, because it says "Exim users may wish to use this". To me, "use this" means "leave it set to YES", but what they actually mean is "Exim users may wish to change this" i.e. set it to NO.
The problem with write_bcc=no is it will leave you with no record of who you have BCC'd in your messages. (When you browse your copyself or sent-mail folder, mutt will not by default show the BCC line anyway, but it will if you examine full headers by pressing h.)
By setting Mutt to use Exim's (or Sendmail's) -t option, you can tell Exim to take the delivery addresses from the message itself not the command line, and also to strip BCC headers. However, there are two problems to work around:
Firstly, Mutt's "Bounce" message command will no longer work: it will just resend the message to its original set of addresses. So I suggest disabling the b key to stop you from running the "bounce" command by accident:
bind index b noop bind pager b noop
Secondly (and more importantly), when running Exim with the -t option, Exim defaults to interpreting the command-line addresses as addresses to remove. Since mutt puts all the delivery addresses on the command line, Exim will end up not delivering to any of them!
Most websites tell you to change your Exim configuration to get around this, but that requires root privileges which you might not have, and it may also break things if some of your users have other mail clients. But there is a way to get around the problem without changing the Exim configuration.
Basically, what we want to do is to stop mutt from putting the email addresses on the command line. There doesn't seem to be a way of telling mutt not to do that, so let's try to make sure that those command-line addresses don't get as far as Exim. That can easily be done by writing a shell script that calls Exim, and get Mutt to call our shell script (and our shell script can ignore the arguments that Mutt puts on its command line). However, it turns out that you don't even have to write a shell script; there's a way you can do it from within .muttrc itself.
What we want to achieve would be something like
WRONG: bash -c sendmail -t #
(I put WRONG: besides that in case anyone's skimming through the article and only looking at the examples.) What that's supposed to do is, get the bash shell to call sendmail -t, and add a # (comment) character so that any email addresses that mutt adds to the command line will be ignored.
The above command won't work though, because bash's -c option requires the entire command to be in one argument i.e. quoted; any other arguments go into its $0, $1 etc. But it's no good quoting the command in .muttrc because mutt's code wouldn't know how to interpret the quotes (if you say "sendmail -t" to pass the single argument sendmail -t, mutt will pass "sendmail as the first argument and -t" as the second argument which will not help).
However, bash does have a built-in variable $IFS which defaults to space. So if we write $IFS instead of space, we can make it work. We don't even need the comment character #, because only the first argument after the -c will be actually interpreted by bash (the others will go into $0 etc, which will be ignored by the command we're going to give). The only thing we need to be careful of is to make sure that mutt does not try to expand the $IFS itself ($IFS is a "special" variable, not usually a real environment variable, so if mutt tries to expand it then it will likely end up with nothing). To stop mutt from trying to expand the $IFS, we must use single quotes ' rather than double quotes " when setting the variable:
set sendmail='/bin/bash -c $1$IFS$2$IFS$3$IFS$4 bash /usr/sbin/sendmail -oem -oi -t'
(The -oem and -oi options are what Mutt uses by default.)
BCC headers are always removed by Exim when a message is submitted via SMTP. Mutt cannot submit messages via SMTP itself, but you can use a small MTA like msmtp to do so, and get Mutt to run msmtp. This can be done even if you don't have root privileges on the system; just compile msmtp in your home directory if necessary, and configure it to send all messages to the real MTA via SMTP.
set sendmail=$HOME/msmtp/bin/msmtp
This method has the advantage that everything works: BCC information is still stored in sent-mail, the Bounce command still works, and BCC is removed from outgoing mails. Additionally, it does not require root privileges or Exim configuration. The only problem is it requires the additional setup of msmtp rather than being a self-contained solution within .muttrc.
After setting things up, I highly recommend you test that BCC headers have indeed been removed. Try sending yourself an email and BCC'ing another address (which doesn't have to exist; just ignore the delivery failure), and then inspect the headers of your email when it is delivered to your inbox. Remember though that Mutt might not be showing BCC headers on incoming email anyway, so press h to view the full headers.
If you want Mutt to show BCC headers on incoming messages (and in your own sent-mail), put this in your .muttrc:
unignore bcc
And you can optionally change the order of headers as well:
unhdr_order * hdr_order From Date: From: To: Cc: Bcc: Subject:
but mentioning Bcc: in hdr_order is not sufficient; you need the above unignore directive as well.
A second "gotcha" of Mutt is the "unconfirmed quit" key, Q (that's a capital Q). I like to automatically delete messages marked for deletion when leaving a folder (the alternative is to lose the deletion marks, so might as well):
set delete = "yes";
but with this setting, pressing Q by mistake will act as an unconfirmed delete-messages-and-quit. The problem? A lower case q is used to quit out of individual-message view and go back to folder view, and the "undelete" key is by default available only from folder view. So if you accidentally hit D to delete a message, then want to undelete it, but you are in message view and need to first go back to folder view before you can use the undelete command, so you press q to go back to folder view, then what happens if you left Caps Lock on by mistake? Goodbye, messages! (Leaving Caps Lock on by mistake is not so easy from a desktop, but it's surprisingly easy from a PDA or phone with an SSH client on it.) Therefore I recommend disabling the capital Q keypress:
bind index Q noop bind pager Q noop
A Mutt "simple search" (as opposed to a full-text search which takes longer) defaults to looking in the From and Subject fields. It's more useful if it also looks in the To field, so you can use your sent-mail folder like an extra address book:
set simple_search = "~f %s | ~t %s | ~s %s";
mutt can be set to automatically display HTML etc using mailcap filters if possible:
set implicit_autoview = 'yes';
but more generally, sometimes you get a message that warrants viewing in a Web browser (for example it might be written in a language that your terminal doesn't display). Mutt can be made to do this in several ways. Since I never print email from Mutt, I set the Mutt "print" command to be a "send this message to a Web browser" command, using the program mhonarc to format the message for the browser:
set print = 'yes'; set print_decode = 'no'; set print_split = 'no'; set wait_key = 'yes'; set print_command="cd $(mktemp -d ~/public_html/mailXXX);sed -e $'s/\\f/From \\\\n/'|LANG=C mhonarc -;[ a\$WEB == a ]&&export WEB=$(hostname -f);echo;echo http://\$WEB/~$(whoami)/$(pwd|sed -e 's-.*/--')/maillist.html;echo Then rm -r $(pwd)";
Note that the above print_command cannot be made much longer, because some versions of mutt will truncate it. That truncation happens after expansion of environment variables, which is why I escaped some of those $ characters. If you need to do more, then make a separate script and call that.
The above command allows you to set the WEB environment variable to the webserver's name if it's different from your hostname. This is useful in some setups if your home directory is mounted over NFS and the Web server is on another machine.
If your MHonarc mangles UTF-8 messages, you might have to set the environment variable M2H_RCFILE to a file containing the contents of http://www.mhonarc.org/MHonArc/doc/rcfileexs/utf-8-encode.mrc.html
It seems that different versions of Mutt default to different sort orders, but you can set it in your .muttrc. I usually use reverse date:
set sort=reverse-date-sent;
Mutt is one of the few mail clients that supports the maildir format. I highly recommend the maildir format, which puts each message in a separate file on the disk.
set mbox_type = 'maildir' ;
Having each message in a separate file means not so much disk activity when changing just one message (i.e. it's faster, and if you're using a flash disk then it's also less wear on the disk). It's also easier to archive old messages etc just by using shell utilities; there's more than one way to do this but I usually use the archivemail program. Furthermore there are many scripts available on the Web which will write new messages to a maildir folder; you can adapt one of these to your mail filtering system and have it add messages to all your folders in the background even while Mutt is accessing them for search etc. (I used Yusuke Shinyama's public-domain pyfetchmail.py and adapted it to fetch IMAP instead of POP by using Python's imaplib module.)
You should probably look through Section 6 of the Mutt manual (and perhaps chapter 3 as well), to check if there are any other options you'd like to set.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/brownss.jpg) Silas Brown is a legally blind computer scientist based in Cambridge UK.
He has been using heavily-customised versions of Debian Linux since
1999.
Silas Brown is a legally blind computer scientist based in Cambridge UK.
He has been using heavily-customised versions of Debian Linux since
1999.
Take one look at /var/log/secure on an Internet-connected server and you'll immediately understand the need for securing your root account. The bad guys are constantly trying 'root' and other usernames, attempting to login to your server using SSH or some other protocol. If you use a simple password, it's only a matter of time before your server is compromised by a password-guessing attack. What can you do?
The best practice is to disallow SSH logins by root, thus eliminating a big part of the risk.
The problem is that doing so also eliminates a lot of convenience for sysadmins and complicates the use of tools such as WinSCP for file copy from your Windows desktop or laptop to your Linux or UNIX server.
A fairly simple solution is to use public/private keypairs for authentication. The public key is stored on the Linux/UNIX server and the private key is stored on your local Windows computer. When you attempt to connect to the Linux/UNIX server from your Windows computer, authentication is done with the keypair instead of a password. Password authentication is actually disabled for root, so no amount of password guessing will work for authentication.
Here's how to do it:
1. Start by downloading the PuTTY Windows installer from http://the.earth.li/~sgtatham/putty/latest/x86/putty-0.60-installer.exe . Run the installer on your local Windows computer.
2. Now, you must generate the keypairs. The PuTTY Windows installer you just ran installs an application called PuTTYgen that you can use to generate the keypairs. The installer probably placed PuTTYgen (and the other PuTTY applications) in Start>>All Programs>>PuTTY.
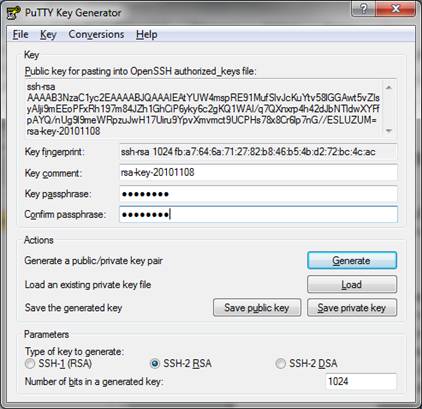
3. When you run PuTTYgen for the first time, you must generate a new keypair. At the bottom of the PuTTYgen window are three parameters choices including SSH-1 (RSA), SSH-2 RSA, and SSH-2 DSA. SSH-2 RSA is the default choice with a default key length of 1024 bits. Longer key lengths are more secure, but require more processing power. 1024 bits is an acceptable compromise at this time (late 2010), but may not be acceptable in the future as computer processing power continues to increase.
4. Click the button labeled Generate to produce your public and private keys. (You must move your mouse pointer over the blank area at the top of the screen to generate some randomness for use in producing the keypair. Just move your mouse pointer in a cirular motion over the blank area until the progress bar reaches the far right side and PuTTYgen generates the keys.)
5. You can now save the private key on your local laptop or desktop computer and copy the public key to the remote Linux/UNIX server.
6. Enter and confirm a passphrase to protect the private key in the two fields in PuTTYgen.
7. Click the button labeled 'Save private key' and select a location on your local hard drive to save the private key. (Remember to protect your private key by storing it securely!) I also like to save my public key as a text file to simplify using it in the future.
8. Copy the gibberish-like text that is the public key (at the top of the PuTTYgen window) and paste it into /root/.ssh/authorized_keys on your server (you might have to create the .ssh directory and you'll probably have to create the authorized_keys file. Note also that the .ssh directory is a hidden directory whose name starts with a period.) If you saved your public key as a text file in the previous step, you can simply copy the contents of that file to /root/.ssh/authorized_keys.

9. On your Linux/UNIX server, inspect /etc/ssh/sshd_config to ensure that RSA authentication and public key authentication are both allowed by modifying three lines in the sshd_config. Depending on your system, you will have to change "no" to "yes" or uncomment the lines to allow the authentication. Also, ensure that the path to the authorized_keys file is set to "%h/.ssh/authorized_keys" and uncomment the line. (I found the three lines at approximately line 43 on a RedHat system and approximately line 29 on a Debian system.) When you're done, the lines should look like this:
RSAAuthentication yes PubkeyAuthentication yes AuthorizedKeysFile %h/.ssh/authorized_keys
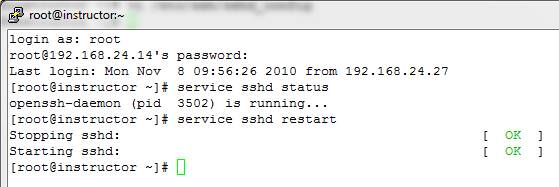
10. In order for the changes to be read into RAM, you must restart SSHD:
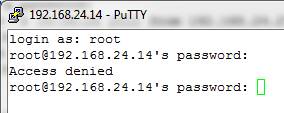
11. If you attempt to log on now with the username root and the root password, the logon attempt will be denied:
12. You must now configure PuTTY to use the public/private key pair for authentication. Open PuTTY, in the left-hand menu area expand SSH and select Auth. On the right-hand side of the window, browse to the location where you stored your private key or simply enter it in the field below "Private key file for authentication:".
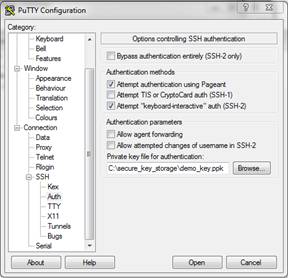
Again, in the left-hand menu, select Session (at the top of the list). On the right-hand side of the screen, enter the IP address or hostname of your Linux server and click the button labeled "Open".
13. When PuTTY connects to the server, enter "root" for the username. You will be prompted for the passphrase you configured for your private key. Enter the correct passphrase and you should be logged on to your server as root.
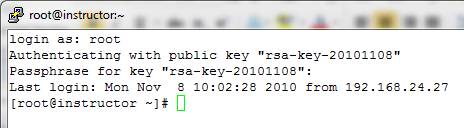
The benefit of performing the preceding steps is that it is nearly impossible for an attacker to log on to your server as root by guessing the password. In order for the attacker to masquerade as root, she or he would have to have your private key and know the passphrase associated with it.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/crawley.jpg)
Don R. Crawley is the author of "The Accidental Administrator: Linux Server Step-by-Step Configuration Guide" and the President of http://soundtraining.net , a Seattle-based IT training firm. He is a veteran IT guy with over 35 years experience in technology for the workplace, and holds multiple certifications on Microsoft, Cisco, and Linux products. Don can be reached at (206) 988-5858 or don@soundtraining.net .

To be or not to be that is the question: Whether 'tis nobler in the mind to suffer The slings and arrows of outrageous fortune, Or to take arms against a sea of troubles And, by opposing, end them. -- William Shakespeare, "Hamlet"
There's a story about a man whose factory is shut down because there is some sort of blockage in one of the pipes. He sends for a plumber who wanders around the factory looking here, listening there and soon steps up to a piece of pipe and gives it a whack with a hammer. Problem fixed. The factory owner is delighted.
However, when a bill for $1000 arrives, he thinks he has been charged quite a lot for very little effort on the plumber's part. He asks for an itemisation.
For tapping pipe $1 For knowing where to tap $999
In the various tasks performed by a sysadmin, problem solving is a lot like the story. Once you know what the problem is, the actual fixing is quite often a doddle.
The real value the sysadmin brings to the table is the ability to diagnose the problem. Importantly, what is presented as the problem is rarely what it seems.
This week I was presented with a problem that epitomises a lot of what has been written above. It started with little more than, "It doesn't work."
In this case, it was, "When I go to URL http://machine06.example.com, it doesn't work." The domain name example.com is just an example; machine06 is one of our computers.
Having learned that my customers can often mislead me, I started by typing the URL into Firefox. Sure enough, it came up with some error.
Unable to connect Firefox can't establish a connection to the server at example.com.
I wasn't surprised, but I need to see it for myself. Sometimes, helpful information will be displayed by the browser, information the customer conveniently neglected to supply.
I'm sure that customers don't always deliberately mislead me. They will neglect to provide information for a host of reasons. They might not have noticed it. They might have seen it, but did not understand it. They might not have appreciated its significance.
Here's another example. Chris recently started working for us as a Help Desk person. I have found him to be a decent, honest, enthusiastic worker. He knows a fair bit, but he is relatively new to Linux. I'm trying to say that I don't think he deliberately tries to mislead me.
"I've copied a file to machine23, but I can't find it."
"Where on machine23 did you send it?" I asked.
"I don't know."
I figured it had to be either his home directory or /tmp. I looked, but there were no new files.
"Show me."
I went back with him to his machine. There it was, on his screen:
scp a_file machine23
It's not something I'd likely pick up if I just spoke to him. I explained why he needed a colon after the hostname and suggested that he get into the habit of typing:
scp a_file machine23:/tmp
I surmise that users look at messages from the perspective of their objectives. If the message does not help them achieve their objectives, they ignore it.
So it's always important to check that you can reproduce the problem - otherwise how will you know when you've fixed it? At the same time, you should check if there are any additional clues.
Satisfied that I had a valid symptom, I set out to get more info. In this case, the next place to look seems pretty obvious. I SSHed into machine06, and tried:
psa | grep http
"psa?" you ask. Think of it as
ps auxw | grep http
"psa" is part of HAL (Henry's Abstraction Layer). I want a list of all processes running on the machine. Because I use it so often, I have abbreviated. But, more importantly, because I work on lots of different platforms, I find it convenient to have a single alias or function which achieves the same result independent of platform (hence the idea of an abstraction layer).
Whenever I login to a new platform for the first time, I bring my HAL (aliases, functions, scripts). If they work, fine. If not, I modify them to handle the new environment. I don't need to make mods very often these days.
machine06 runs Linux. Had it been a Sun, psa would have translated to
/usr/ucb/ps -auxw
(I could also use "ps -ef".)
Back to the story.
Normally, I would expect output like the following:
root 12344 0.0 2.2 29932 16516 ? Ss Aug21 0:03 /usr/sbin/httpd apache 21394 0.0 1.5 29932 11244 ? S Oct05 0:00 /usr/sbin/httpd apache 21395 0.0 1.5 29932 11208 ? S Oct05 0:00 /usr/sbin/httpd
There might be more lines like the last two, depending on how Apache had been set up.
(It's also true that machine06 might have been running some other software and not Apache. I assume Apache because I have some idea of what our organisation typically does.)
Well, if Apache is not running, that could account for the problem. I guess I could just restart Apache.
But why is it not running?
cd /var/log/httpd ls -lat | head
(I actually typed "dth", not the second line. More HAL.)
There were several files including error_log, error_log.0, error_log.1, ... and similar for access_log. As I write this, with the benefit of knowing the answer, there were heaps more clues which provided "back story" to the problem.
But at the time, I was only interested in recent files. error_log was most recent, and not very large:
cat error_log.2 [Wed Oct 06 01:30:14 2010] [crit] (28)No space left on device: mod_rewrite: could not create rewrite_log_lock Configuration Failed!
Even though I preach not to jump to conclusions, in the heat of the chase I confess that I sometimes do. In this case, the seed had been planted. The previous day I had come in to work to discover that outbound mail was not working because a disk had filled. Here was another message which seemed to say the same thing: "No space left on device".
I cursed whoever was responsible for the message. "Why doesn't is say which device?"
The second and third lines did not make much sense to me. Since I was predisposed to believe that a disk had filled (again), I rushed forward:
df -h Filesystem Size Used Avail Use% Mounted /dev/hda5 3.9G 909M 2.8G 25% / /dev/hda1 99M 56M 38M 60% /boot none 485M 0 485M 0% /dev/shm /dev/hda7 41G 35M 39G 1% /tmp /dev/hda2 53G 3.4G 47G 7% /usr /dev/hdb1 111G 102G 3.4G 97% /usr/local /dev/hda3 9.7G 5.4G 3.8G 59% /var
Hmm, not very helpful. None of the disks is close to full.
Perhaps a disk was full and is no longer full. I looked through all the earlier error logs:
ls -la error_log.* -rw-r--r-- 1 root root 132 Oct 6 01:30 error_log.2 -rw-r--r-- 1 root root 132 Oct 5 01:30 error_log.3 -rw-r--r-- 1 root root 132 Oct 4 01:30 error_log.4 -rw-r--r-- 1 root root 132 Oct 3 01:30 error_log.5 -rw-r--r-- 1 root root 132 Oct 2 01:30 error_log.6 -rw-r--r-- 1 root root 132 Oct 1 01:30 error_log.7 -rw-r--r-- 1 root root 132 Sep 30 01:30 error_log.8 -rw-r--r-- 1 root root 132 Sep 29 01:30 error_log.9
They were all similar; only the date was different.
That's really odd. This problem has been around for over a week, yet I'm only hearing about it now. And, if my tentative hypothesis is correct, the disk was full for all that time, but today there is space. Curiouser and curiouser, to quote Alice.
I've gone through all the information I can find, and I don't look like I'm any closer to a solution.
Here's the next difficulty. I think it's unarguable that computer systems are getting more and more complex. And I suspect technology is changing more and more rapidly. The producers of all this change and complexity do the best they can. In particular, they try to build resilience. What they don't get time to do is craft perfection.
Often errors are encountered, reported and brushed aside. I see countless warnings, errors and the like which seem to have no impact on functionality.
It may just be the case that the error "No space" is not responsible for, or relevant to, the problem I'm trying to solve. I don't have enough logs to go back to a time when things were working. (I do *now*, of course, because before I started writing this article I solved the problem. So I could look at recent logs.)
There have been times when I have been confronted with a problem. After a certain amount of research, I come to the conclusion that the problem is caused by one of two possible scenarios. But I can get no further. No amount of cerebration enables me to split the possibilities. And I'm still missing the vital next step.
Eventually, I construct an experiment or test to confirm or deny one of the two possibilities. As soon as the test rejects one of the possibilities, I get a flash of realisation and understanding of what's going on in the other scenario: what's wrong and the path to pursue for a fix.
Why has my state of mind changed so dramatically? Why could I have not come up with the flash simply by assuming that scenario 1 was false?
The question is not rhetorical. I do not have an answer.
In this case, the two scenarios are
I don't believe that the problem is to do with disk space. But I've run out of ideas, and the thought of the error message is going to keep me from moving forward with clarity.
So, to try to get more information:
/etc/init.d/httpd status httpd is stopped /etc/init.d/httpd start Starting httpd: [FAILED]
(There might have been a bit more. I'm doing this bit out of my head. It's a bit hard to bring down production functionality just to make a point.)
Looking in the log, I saw a recent time stamp and the "No space" message.
OK, I think that that proves it's not disk space.
At this point, one could go one of two ways. I went both ways, but the order in which I worked reflects my predilections.
I want to understand the problem, and I figure I have a better chance of understanding if I look under the covers.
truss /etc/init.d/httpd start
In this case, "truss" is not "truss" (which is a Solaris command) but rather "strace". And it's a much more complicated mapping than that. (More HAL.)
90% into the strace:
24313 semget(IPC_PRIVATE, 1, IPC_CREAT|0600) = -1 ENOSPC (No space left on device)
I looked up the man page for semget:
ENOSPC A semaphore set has to be created but the system limit for
the maximum number of semaphore sets (SEMMNI), or the system
wide maximum number of semaphores (SEMMNS), would be
exceeded.
When is a door not a door? When it's ajar.
When is "No space" not "No space"? Here we have the answer.
All platforms have the notion of error numbers. Solaris environments document these in Intro(2). Fedora (all Linux distros?) document them in errno(3).
Further, every system call and every library call has its own section of the man page to document relevant error numbers.
Somewhere between, there is scope for more unintended misdirection.
On the one hand, it's highly commendable that different system/library routines return the same error number for the same sort of error. On the other hand, the universe does not always divide into such simple consistent components.
In this case, it seems that someone decided that running out of space in a table should return ENOSPC. Looked at from that point of view, the rationale seems reasonable.
However, looked at from the perspective of a long-suffering sysadmin, this noble ambition has simply misled me. It has added to my sea of troubles.
There's one more turn of the wheel left.
I now understand the problem. I probably know more about the problem than I ever wanted to. But I'm still no nearer to a solution.
Mr. Internet is your friend. I looked up "mod_rewrite: could not create rewrite_log_lock" and found this article: http://carlosrivero.com/fix-apache---no-space-left-on-device-couldnt-create-accept-lock
Perhaps because by now I had a good insight into the problem, I immediately recognised the relevance of this webpage.
I checked:
ipcs -s | grep apache ------ Semaphore Arrays -------- key semid owner perms nsems 0x00000000 8159232 apache 600 1 0x00000000 8192001 apache 600 1 ...
Sure enough, there were lots of semaphore arrays, owned by apache.
Since Apache was not running it seemed safe to delete them using the script provided in the article:
ipcs -s | grep apache | perl -e 'while (<STDIN>)
{ @a=split(/\s+/); print `ipcrm sem $a[1]`}'
After that, I was able to start Apache:
/etc/init.d/httpd start
Starting httpd: [ OK ]
Back at my Firefox, I confirmed that I could visit http://machine06.example.com and get a reasonable response.
Finally, because this time I remembered to be methodical, I wrote some notes for my help system in a file called help_apache_http_no_space.
With a bit of luck, if I have a problem in the future, I will visit my help system to check if there is any relevant material. Perhaps I'll find useful information. Instead of rediscovering the solution ab initio, I can skip to the last page and simply type the command to delete the Apache semaphores.
If someone asks me how I can charge so much for typing the 'ipcs' command above, I can respond along the following lines:
for typing the command $1 for knowing which command to type $999
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/grebler.jpg)
Henry has spent his days working with computers, mostly for computer manufacturers or software developers. His early computer experience includes relics such as punch cards, paper tape and mag tape. It is his darkest secret that he has been paid to do the sorts of things he would have paid money to be allowed to do. Just don't tell any of his employers.
He has used Linux as his personal home desktop since the family got its first PC in 1996. Back then, when the family shared the one PC, it was a dual-boot Windows/Slackware setup. Now that each member has his/her own computer, Henry somehow survives in a purely Linux world.
He lives in a suburb of Melbourne, Australia.
 If you are new to Linux you may never have tried any desktop environments
beyond Gnome and KDE. If you have been in the Linux world for
a while, odds are you are aware of the fact that several
other desktop environments exist. During the three and a half years I
have spent using Linux, I have tried every different type of desktop under
the sun and of them all, Enlightenment's E17 is my personal
favorite. The following are a few reasons why it may
be worth breaking out of your Gnome/KDE comfort zone to give E17 a try:
If you are new to Linux you may never have tried any desktop environments
beyond Gnome and KDE. If you have been in the Linux world for
a while, odds are you are aware of the fact that several
other desktop environments exist. During the three and a half years I
have spent using Linux, I have tried every different type of desktop under
the sun and of them all, Enlightenment's E17 is my personal
favorite. The following are a few reasons why it may
be worth breaking out of your Gnome/KDE comfort zone to give E17 a try:
1.) - Low Resource Consumption
The suggested minimum for running E17 is 16MB of RAM and a 200mhz ARM processor for embedded devices. The recommended RAM is 64MB (and a stripped down version of E17 can be happy running on 8MB of RAM). From personal experience, E17 utilizes around 100MB of RAM on a fully loaded desktop install - meaning that if you have at least 128MB of system memory in your computer, E17 will function fantastically. Because of this, E17 makes for a great choice on older computers.
2.) - It is Fast
One of the reasons many people use Linux in the first place is because it is quicker than some other operating systems. With E17, your Linux desktop will run faster than ever. E17's low system requirements leave more power for the rest of your applications to utilize.
3.) - Desktop Effects on All Systems
Don't ask me how it is done, but E17 provides elegant window effects and desktop transitions regardless of your hardware and driver setup. Intel, nVidia, or ATI chipset; closed source or open source driver - they will all give you a sleek looking desktop with E17. With the itask-ng module, E17 can also provide a dock launcher that has a sleek look without a need for a compositing window manager to be enabled.
4.) - It is Elegant
If configured properly, E17 can be so much more than just a desktop environment. In fact, many consider it to be a work of art. E17 is designed to be pretty, and it does a fantastic job to this end.
5.) - It is 100% Modular
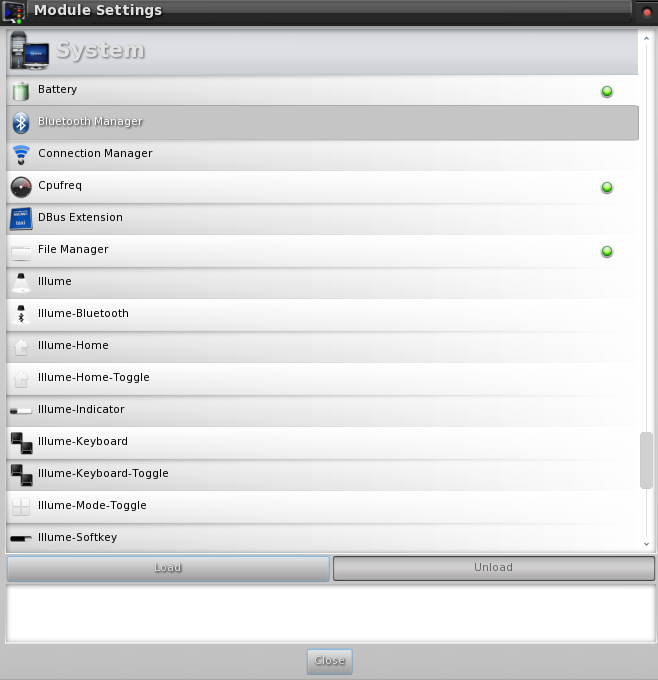
Not using some of the features E17 has and don't want them taking up unnecessary resources? Not a problem! E17 allows you to easily load and unload each and every part (module) of the desktop through the configuration menu. This way, only the parts of the system you are using are loaded at start-up.
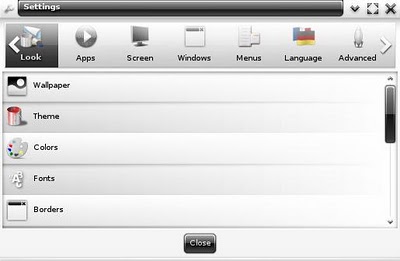
6.) - It is 100% Configurable
Should you want to, you can easily spend days tinkering with your E17 configuration. You can adjust anything and everything. Most notably appearance-wise, E17 allows you to easily theme each individual module with a different theme.
7.) - Core ELF are now Beta
For many years now, people have been saying that they will not use Enlightenment because it is "unstable". At the start of this month, October 3rd, the Enlightenment foundation finally released a "beta" version of their libraries. To quote the Enlightenment homepage:
8.) - You Don't have to Compile It Anymore
Just like many other open source applications these days, E17 can be downloaded as an installation package for your favorite distro. In fact, there are a couple of different pre-compiled Linux distros that use E17 as their default Window manager. These include:
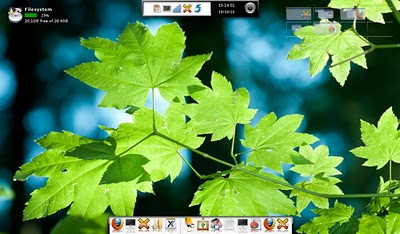
Pretty, isn't it? If I've persuaded you to give E17 a try, let me know what you think about it. Also, if you are looking to chat in real time about Enlightenment - drop by #e over on Freenode!
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/hoogland.jpg)
I am currently a full time student working my way through a math education program on the south side of Chicago. I work in both theatre & computer fields currently. I am a huge believer in Linux and believe we will see Microsoft's dominant market share on the personal computer crumble at some point in the next twenty years. I write a good deal about technology and you can always find my most current thoughts/reviews/ramblings at http://jeffhoogland.blogspot.com/
By Tom Parkin
One of my favourite things about the Linux desktop experience is how modular and flexible it is. If the attractive GUIs offered by comprehensive desktop environments such as GNOME or KDE don't meet your needs, it is relatively simple to swap them out for something different. Given enough time and appropriate motivation it is possible to create a completely bespoke desktop.
In order to support my day-to-day work as a software engineer I have done exactly this, replacing the GUI on my Fedora development box with something dedicated to my requirements. In this article I will discuss the components that make up my programming desktop, and how they help me do my job more efficiently.
I spend most of my time working with a text editor, a compiler, and a command prompt. Ideally, my desktop should be optimised for the most efficient access to these core tools. Beyond that, my desktop should keep out of my way: to program effectively I need to be able to concentrate.
To fulfil these basic requirements, I have developed my desktop around the following guiding principles:
In order to meet my requirements for a programming desktop, I have broken the desktop down into a number of components. The most obvious are the window manager, and the applications. To create a truly streamlined environment, I have also developed or integrated a number of tools which complement my basic desktop. These include scripts for workflow management, wrappers to remove the rough edges from some tools I use, and some "fit and finish" utilities to complete the package.
The fundamental choice in designing a desktop is that of the window manager.
For my programming desktop, I use a very small and simple window manager called dwm. dwm is a tiling window manager along the lines of xmonad, wmii, ion, and awesome wm. Although the tiling paradigm takes a little adjustment to get used to, I find it a great fit for programming tasks as it makes it easy for me to manage lots of terminal windows.
In addition to the benefits of the tiling layout, dwm boasts a number of other attractive features. Firstly, it is entirely keyboard driven, which means that I can start new applications, close windows, change tiling layouts and switch between virtual desktops without needing to touch the mouse. Secondly, it is very small and sleek (consisting of around 2000 lines of code in total), which means it is very fast to start up and provides no bells or whistles to distract me from my work. Finally, in a particularly hacker-centric design decision, dwm is configured entirely through modifying the header file and recompiling. What better advertisement could there be for a true programming environment?
No desktop is complete without applications, and no programmer's toolkit would be complete without an editor! Here I am much more conventional than in my window manager choice. All my editing needs are met by the venerable vim. Vim starts up fast, is very configurable, and offers many powerful commands to help me get the most out of my keystrokes. In conjunction with vim, I use ctags and cscope to help navigate source trees. The latter are made easily accessible via an alias in my ~/.bashrc:
alias mktags='ctags -Rb && cscope -Rb'
My desktop application requirements are rounded off with a combination of mutt for email access and Firefox for web browsing. Firefox is somewhat customised by means of the excellent vimperator extension, which allows me to drive Firefox from the keyboard.
The window manager and applications are only the building blocks of a productive working environment. In order to make the desktop work for me, I have created a number of tools specific to my workflow. When programming, this workflow is broadly as follows: check out a sandbox from revision control; make some modifications; test those modifications; and check the resulting code back in. The only bits I am really interested in, however, are the making and testing of changes. The rest is just an overhead of doing the interesting work.
Happily, the Linux command line makes it easy to reduce the burden of this overhead via scripting. I have developed three scripts I use on a daily basis to manage the sandboxes I'm working on:
Although freshen, workroot and stale form an important part of my working environment, the inner details of how they do what they do are rather project-specific and unlikely to be of wider interest. As such, and in the interests of brevity, I won't provide code listings for these scripts here.
In addition to the scripts I've developed to support my daily workflow, I have also developed various wrappers which make certain programming tools more convenient. The main bugbear in this department is CVS, whose lacklustre diff and status output obscures a lot of potentially useful information. To improve matters I use shell scripts and aliases to mold the raw output from CVS into something more palatable. My cvs diff wrapper, cvsdiff, pipes output from the cvs diff command through a colorising script and a pager. Similarly, my cvs status wrapper parses the output of the cvs status command to display it in a more readable format.
cvsdiff utilises the fantastic colordiff project to display nicer diff output. Since the script for this is so short I define it as an alias in my ~/.bashrc file. Note the use of the -R argument to GNU less. This instructs less to pass control characters through in "raw" mode, meaning the color output from colordiff is preserved.
alias cvsdiff='cvs diff -u 2>&1 | grep -v "^\(?\|cvs\)" | colordiff | less -R'
cvstatus uses awk (or gawk on my Fedora machine) to parse the verbose output of the cvs status command. The gawk code is wrapped in a simple bit of shell script to allow the easy passing of command line arguments. I install this script in ~/bin, which is added to my $PATH in ~/.bashrc.
#!/bin/sh
CARGS="vf"
VERBOSE=0
FULLPATH=0
while getopts $CARGS opt
do
case $opt in
v) VERBOSE=1;;
f) FULLPATH=1;;
esac
done
cvs status 2>&1 | awk -v verbose=$VERBOSE -v fullpath=$FULLPATH '
function printline(path, status, working_rev, repos_rev, tag) {
# truncate path if necessary
if (!fullpath) {
plen = length(path);
if (plen >= 30) {
path = sprintf("-%s", substr(path, (plen-30+2)));
}
}
printf("%-30s %-25s %-15s %-15s %-20s\n", path, status, working_rev, repos_rev, tag);
}
BEGIN {
do_search=0;
do_print=1;
state=do_search;
printline("Path", "Status", "Working rev", "Repository rev", "Tag");
printline("----", "------", "-----------", "--------------", "---");
}
# Track directories
/Examining/ { dir=$4; }
# Handle unknown files
/^\?/ {
fn=$2;
status="Unknown";
wrev="??";
rrev="??";
tag="No tag";
state=do_print;
}
# For known files capture the filename, status, revision info and tag
/^File/ {
status=$0;
gsub(/^.*Status: /, "", status);
if (status ~ /Locally Removed/) {
fn=$4;
} else {
fn=$2;
}
if ( (verbose && status ~ /Up-to-date/) || status !~ /Up-to-date/ ) {
state=do_print;
}
}
/Working revision/ { wrev=$3; }
/Repository revision/ { rrev=$3; }
/Sticky Tag/ { tag=$3; }
# Print handling
(/?/ || /Sticky Options/ || /======/ ) && state == do_print {
path = sprintf("%s/%s", dir, fn);
printline(path, status, wrev, rrev, tag);
state=do_search;
}
'
The final components of my programming desktop provide some of the functionality typically found in graphical file managers such as Nautilus, Dolphin or Thunar.
For quick and easy exploration of directory hierarchies, I use tree. Although there are much better tools for finding specific files in a directory structure, tree excels in presenting an overall view by means of intelligent indentation and coloured output.
In order to conveniently mount hot-pluggable media such as USB flash drives, I use the pmount and pumount wrapper utilities. These have been developed to allow an unprivileged user to mount a local volume, and are much more user-friendly than manually messing about with sudo.
Finally, I use a simple script of my own devising to make mounting and unmounting network shares more convenient. This allows me to hide the differences between different network shares behind a common interface. My script is based around a per-share configuration file which describes the share to be mounted. Currently CIFS and sshfs shares are supported. Since the script's job is to handle mounting volumes, I named it mountie.
The configuration file format for mountie follows the INI "token = value" syntax used by e.g. the Samba project. Valid configuration tokens are as follows:
For example:
type = sshfs user = tom host = fileserver.site.internal path = /export/media/shared mount = ~/fileserver
The bash script for mountie itself is as follows:
#!/bin/bash
#
# mountie
#
# Mount remote filesystems
#
ACTION=mount
HOST=
REMOTE_PATH=
MOUNTPOINT=
log() { echo "$@"; }
err() { log "$@" 1>&2; false; }
die() { err "$@"; exit 1; }
# $1 -- user
# $2 -- host
# $3 -- path
# $4 -- mount point
sshfs_do_mount() { mkdir -p ${4} && sshfs -o nonempty ${1}@${2}:${3} ${4}; }
sshfs_do_umount() { fusermount -u ${4}; }
cifs_do_mount() { mkdir -p ${4} && sudo -p "[sudo] $(whoami)'s password: " mount -t cifs \\\\${2}\\${3} ${4} -o username=${1}; }
cifs_do_umount() { mkdir -p ${4} && sudo -p "[sudo] $(whoami)'s password: " umount ${4}; }
# $1 -- config file path
config_get_type() { grep "type" $1 | cut -d"=" -f2; }
config_get_user() { grep "user" $1 | cut -d"=" -f2; }
config_get_host() { grep "host" $1 | cut -d"=" -f2; }
config_get_path() { grep "path" $1 | cut -d"=" -f2 | tr -d " "; }
config_get_mountpoint() { grep "mount" $1 | cut -d"=" -f2; }
show_usage() {
log "Usage: [-uh] $(basename $0) "
}
#
# Entry point
#
while getopts "uh" opt
do
case $opt in
u) ACTION=umount ;;
h) show_usage; exit 0 ;;
*) die "Unknown option" ;;
esac
done
shift $((OPTIND-1))
if test -z "$1"
then
show_usage
exit 0
fi
for config in $@
do
if test -f $config
then
$(config_get_type $config)_do_$ACTION \
$(config_get_user $config) \
$(config_get_host $config) \
$(config_get_path $config) \
$(config_get_mountpoint $config) || die "Failed to mount $(config_get_host $config):$(config_get_path $config)"
else
err "Cannot locate configuration file $config"
fi
done
I've developed my programming desktop to remove distractions, increase efficiency, and to support my workflow. This has been achieved by combining many excellent GUI and command line tools. Where my work has demanded a more specialist tool than the free software ecosystem has provided I have been able to harness the scripting abilities of BASH and gawk to create my own.
Although my programming desktop works well for me for the majority of what I do, it isn't the only desktop I use. On the contrary, there are several applications which are ill served by dwm's tiling paradigm, especially those using the "many floating toolbox windows" UI design pattern, such as the Gimp, Dia or OpenOffice. When I find myself called to such use applications, or even when I fancy something with a bit more graphical bling than dwm offers, I sometimes use a GNOME or Xfce desktop instead.
An article like this one tends to present the subject as though it were a complete and finished work, the reproduction of which can be intimidating to contemplate. Rest assured, however, that my desktop hasn't been conceived that way. Instead, I've developed this environment over time in an evolutionary manner, gradually removing irritations and inefficiencies. I fully expect it will change again in the future, and I look forward to the new tools I might discover, and the new scripts I will develop to make my life ever easier. Most of all, I hope some of the ideas I've presented in this article may give you some ideas for sculpting your own perfect environment.
| Share |
|
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/parkin.jpg)
Tom Parkin has been fascinated by the inner workings of digital technologies ever since his father brought home a VIC-20 sometime in the mid-eighties. Having spent most of his childhood breaking computers in a variety of inventive ways he decided to learn how to fix them again, a motivation which lead him to undertake an MEng degree in Electronic Systems Engineering in 2000. Since graduating he has pursued a career in embedded software engineering, and now feels that he has probably been responsible for more working computers than broken ones.
Tom was introduced to Linux when a friend lent him a thick stack of Mandriva installation CDs, and he has been using Open Source software ever since. Like most Linux users, Tom has tried many different distributions but is currently settled with Fedora at work and Crunchbang on his home machine.
When not tinkering with computers and Linux, Tom enjoys exploring the great outdoors on bike or on foot, and making music.
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
 Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site, http://penguinpetes.com/Doomed_to_Obscurity/.
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?

![[cartoon]](misc/xkcd/tech_support.png "I recently had someone ask me to go get a computer and turn it on so I could restart it. He refused to move further in the script until I said I had done that.")



